
Arsitektur: Merancang Arsitektur Read-Heavy API untuk Product Page Skala Tinggi
Pada banyak aplikasi modern—terutama e‑commerce, katalog, atau content platform—product detail page adalah endpoint dengan traffic read paling tinggi. Masalah klasiknya hampir selalu sama:
- Read QPS sangat besar
- Database resource terbatas
- Banyak side-effect ikut terjadi (view count, last viewed, analytics)
- Data yang ditampilkan bukan satu jenis, tapi gabungan banyak domain
Jika semua ini diproses secara sinkron dan langsung ke database, sistem akan cepat mencapai bottleneck.
Artikel ini membahas pendekatan arsitektur yang pragmatis, scalable, dan production-proven untuk menangani read-heavy API, khususnya product page.
Gambaran Arsitektur yang Direkomendasikan
Bagan berikut memperlihatkan pendekatan yang disarankan: read path yang ringan, ter-cache, dan side-effect yang dipisahkan secara async.
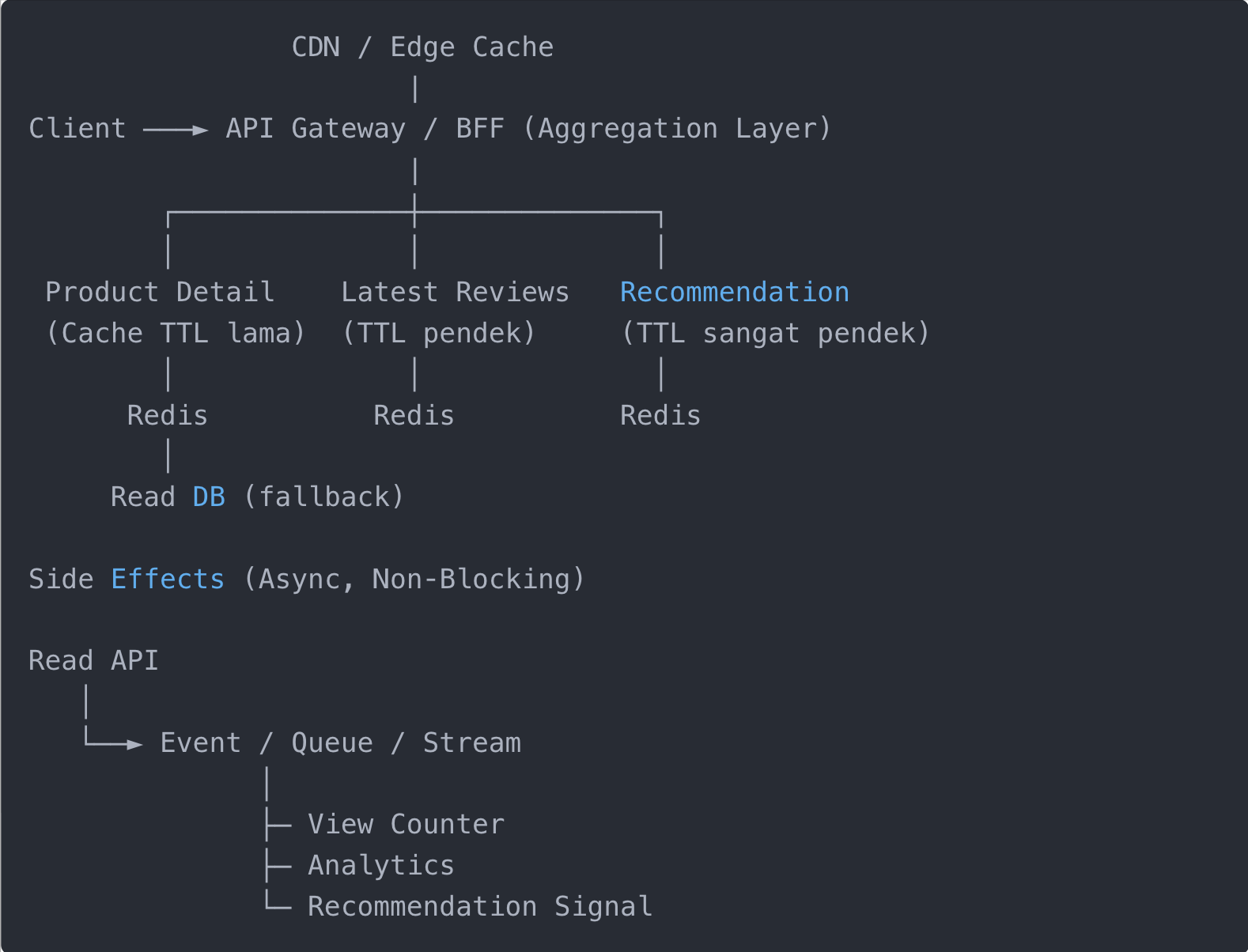
Prinsip Utama: Pisahkan Read Murni dan Side Effect
Read API Harus Deterministik dan Murah
Read API yang sehat memiliki karakteristik:
- Deterministik (request yang sama → response yang sama)
- Tidak memicu transaksi write
- Tidak bergantung pada proses eksternal
- Aman untuk di-cache agresif
Begitu read API mulai:
- menulis ke database
- mengupdate counter sinkron
- memanggil service lain untuk analytics
maka read path tersebut kehilangan sifat skalabilitasnya.
Product page idealnya adalah pure read operation. Artinya:
- Tidak mengubah state utama
- Tidak menunggu proses lain selesai
- Tidak memicu transaksi berat
Contoh side-effect yang harus dikeluarkan dari jalur utama:
- Save view
- Update last viewed
- Analytics event
- Recommendation signal
Pendekatan yang sehat adalah fire-and-forget event ke message broker atau queue.
Hasilnya:
- Latency rendah
- Throughput tinggi
- Database tidak tersedak
Cache sebagai Senjata Utama
Cache Bukan Optimasi, Tapi Desain
Pada sistem dengan read operation sangat tinggi, cache bukan lagi lapisan tambahan, melainkan bagian dari desain arsitektur itu sendiri. Tanpa cache, database—sebaik apa pun dioptimalkan—akan tetap menjadi bottleneck.
Hal penting yang sering terlewat adalah: cache harus dirancang sejak awal, bukan ditempel belakangan. Ini mencakup:
- Penentuan cache key yang stabil
- TTL yang sesuai karakteristik data
- Strategi invalidasi yang jelas
- Observability terhadap cache hit/miss
Cache yang buruk bisa lebih berbahaya daripada tidak ada cache sama sekali.
Pada sistem read-heavy, cache bukan optimasi tambahan—cache adalah fondasi.
Layer Cache yang Disarankan
CDN / Edge Cache Cocok untuk response yang relatif stabil (HTML / JSON product detail).
Application Cache (Redis / Memcached) Menyimpan hasil query per domain data.
Database Digunakan hanya saat cache miss.
Target realistis:
80–95% traffic berhenti di cache
Kenapa Product Page Sebaiknya Tidak Satu Endpoint
Masalah TTL Terendah Menentukan Segalanya
Jika satu endpoint menggabungkan semua data product page, maka TTL cache endpoint tersebut harus mengikuti data yang paling cepat berubah.
Akibatnya:
- Product detail yang jarang berubah ikut sering di-refresh
- Cache churn tinggi
- DB load meningkat tanpa perlu
Ini adalah hidden cost yang sering baru terasa saat traffic sudah tinggi.
Satu product page biasanya terdiri dari beberapa domain data:
| Komponen | Karakteristik | Perubahan | TTL Ideal |
|---|---|---|---|
| Product detail | Stabil | Jarang | Panjang |
| Price / stock | Sensitif | Sering | Pendek |
| Latest review | Append-only | Sedang | Pendek–menengah |
| Recommendation | Dinamis | Sangat sering | Sangat pendek |
Jika semua dipaksa dalam satu endpoint:
- TTL ditarik ke yang paling sensitif
- Cache menjadi tidak efektif
- Setiap perubahan kecil memicu invalidasi besar
Pendekatan yang Lebih Sehat: Composable Read APIs
Domain-Oriented Read Model
Composable Read API pada dasarnya adalah penerapan ringan dari CQRS (Command Query Responsibility Segregation) di sisi read.
Setiap endpoint:
- Mewakili satu domain data
- Bisa memiliki schema dan storage berbeda
- Tidak harus 100% konsisten dengan write model
Pendekatan ini memberi kebebasan untuk:
- Denormalisasi agresif
- Materialized view
- Bahkan storage berbeda (Redis-only, read DB, atau search index)
Decision Table: Kapan Perlu Split Endpoint?
Tabel berikut dapat digunakan sebagai panduan praktis untuk memutuskan apakah sebuah product page sebaiknya dipecah menjadi beberapa endpoint atau tetap satu endpoint.
| Pertanyaan Teknis | Jika YA | Jika TIDAK |
|---|---|---|
| Apakah data di halaman memiliki TTL ideal yang berbeda jauh? | Split endpoint | Masih aman satu endpoint |
| Apakah sebagian data berubah jauh lebih sering dari yang lain? | Split endpoint | Satu endpoint cukup |
| Apakah sebagian data bisa di-cache sangat lama, sementara yang lain tidak? | Split endpoint | Satu endpoint masih masuk akal |
| Apakah kegagalan satu bagian data tidak boleh merusak seluruh halaman? | Split endpoint | Satu endpoint bisa dipertimbangkan |
| Apakah traffic read sudah tinggi dan cache churn mulai terasa? | Split endpoint | Tunda split (belum perlu) |
| Apakah frontend/client siap menangani banyak request? | Gunakan BFF + split endpoint | Pertahankan satu endpoint |
| Apakah domain data sudah jelas dan stabil? | Split endpoint | Jangan split dulu |
Rule praktis:
Jika lebih dari dua pertanyaan di atas jawabannya YA, maka split endpoint biasanya adalah keputusan yang tepat.
Domain-Oriented Read Model
Composable Read API pada dasarnya adalah penerapan ringan dari CQRS (Command Query Responsibility Segregation) di sisi read.
Setiap endpoint:
- Mewakili satu domain data
- Bisa memiliki schema dan storage berbeda
- Tidak harus 100% konsisten dengan write model
Pendekatan ini memberi kebebasan untuk:
- Denormalisasi agresif
- Materialized view
- Bahkan storage berbeda (Redis-only, read DB, atau search index)
Alih-alih satu endpoint besar, gunakan beberapa endpoint kecil berdasarkan domain:
GET /product/{id}/detail
GET /product/{id}/price
GET /product/{id}/reviews/latest
GET /product/{id}/recommendations
Setiap endpoint:
- Memiliki cache sendiri
- TTL sesuai karakteristik data
- Mudah diskalakan dan diobservasi
Jangan Lempar Kompleksitas ke Client: Gunakan BFF
BFF Sebagai Boundary Kontrak
BFF bukan sekadar aggregator, tapi boundary kontrak antara frontend dan kompleksitas backend.
Tanggung jawab BFF mencakup:
- Parallel fetching
- Timeout isolation (satu domain gagal tidak merusak seluruh page)
- Partial response
- Default/fallback value
- Versioning response tanpa memecah client
Dengan BFF, perubahan internal backend tidak bocor ke frontend.
Jika frontend harus memanggil banyak endpoint sendiri:
- Latency meningkat
- Error handling kompleks
- UX mudah terdampak
Solusinya adalah Backend for Frontend (BFF).
BFF bertugas:
- Menggabungkan response
- Fetch secara paralel
- Menyediakan fallback
- Menjaga contract tetap sederhana untuk client
Client tetap satu request, backend tetap modular.
Strategi Cache per Endpoint (Contoh Praktis)
Product Detail
- TTL: 10–30 menit
- Invalidation: event
ProductUpdated - Key:
product:detail:{id}
Latest Review
- TTL: 30–120 detik
- Key:
product:reviews:latest:{id}
Recommendation
- TTL: 5–15 detik atau tanpa cache
- Key:
product:recommendation:{id}:{segment}
Price / Stock
- TTL: 5–10 detik
- Atau gunakan stale-while-revalidate
Anti-Pattern yang Sering Terjadi pada Read-Heavy Product Page
Bagian ini penting untuk melengkapi pembahasan sebelumnya. Banyak sistem mengalami masalah skalabilitas bukan karena kurang fitur, tetapi karena terjebak pada pola desain yang kelihatannya sederhana namun berbahaya di skala besar.
Anti-Pattern 1: Satu Endpoint Gemuk untuk Semua Kebutuhan
Contoh:
GET /product/{id}
Endpoint ini:
- Mengambil detail produk
- Mengambil harga & stok
- Mengambil review
- Mengambil rekomendasi
- Sekaligus menulis view count
Masalah yang muncul:
- TTL cache dipaksa mengikuti data paling sensitif
- Cache churn tinggi
- Setiap perubahan kecil memicu invalidasi besar
- Latency tidak stabil
Ini adalah anti-pattern paling umum pada sistem yang awalnya kecil lalu tumbuh cepat.
Anti-Pattern 2: Side Effect Sinkron di Jalur Read
Contoh yang sering dianggap “sepele”:
- Increment view counter di DB
- Update last viewed user
- Insert analytics event langsung
Dampaknya:
- Read API kehilangan sifat deterministik
- Latency naik seiring traffic
- DB write contention
Side-effect seperti ini harus selalu async dan dikeluarkan dari critical path.
Anti-Pattern 3: Mengandalkan Database sebagai Cache
Ciri-cirinya:
- Query dioptimasi habis-habisan
- Index ditambah terus
- Tapi read QPS tetap langsung ke DB
Masalahnya:
- Database bukan komponen murah untuk read masif
- Vertical scaling cepat mentok
- Setiap spike traffic langsung terasa
Jika database mulai “terasa berat”, biasanya masalahnya bukan di query, tapi di absennya cache yang efektif.
Anti-Pattern 4: Terlalu Dini Memakai Elasticsearch untuk Detail Page
Kesalahan umum:
- DB mulai berat → langsung pindah ke Elasticsearch
- ES dipakai sebagai primary read store untuk detail by ID
Risikonya:
- Konsistensi data sulit dijelaskan
- Operasional cluster bertambah kompleks
- Debug data mismatch memakan waktu
Elasticsearch seharusnya digunakan karena kebutuhan query, bukan sekadar performa.
Anti-Pattern 5: Membebankan Orkestrasi ke Frontend
Contoh:
- Frontend harus memanggil 5–6 endpoint
- Frontend menggabungkan response
- Frontend meng-handle timeout satu per satu
Dampaknya:
- UX tidak stabil
- Logic tersebar di client
- Sulit melakukan perubahan backend
Masalah ini seharusnya diselesaikan dengan BFF, bukan dengan memperumit client.
Tentang Elasticsearch: Perlu atau Tidak?
Elasticsearch Bukan Shortcut Skala
Elasticsearch sering dianggap solusi cepat saat database mulai berat. Padahal, ia bukan pengganti cache dan bukan solusi read murah untuk primary-key lookup.
Beberapa risiko jika terlalu dini menggunakan Elasticsearch:
- Operasional lebih kompleks (cluster, shard, reindex)
- Konsistensi eventual yang sulit dijelaskan ke bisnis
- Debugging data mismatch
Elasticsearch seharusnya masuk karena kebutuhan query, bukan karena performa semata.
Elasticsearch sangat cocok untuk:
- Full‑text search
- Filtering kompleks
- Listing produk
Namun untuk:
GET /product/{id}
Biasanya tidak perlu di tahap awal karena:
- Eventually consistent
- Operational cost tinggi
- Bukan source of truth
Gunakan Elasticsearch jika use case-nya memang search-driven, bukan sekadar primary key lookup.
Urutan Evolusi yang Bijak
Jangan Lompat ke Kompleksitas Tinggi Terlalu Dini
Banyak sistem gagal bukan karena kurang canggih, tapi karena terlalu cepat kompleks.
Urutan evolusi yang sehat:
- Pisahkan read dan side-effect
- Terapkan cache berlapis dengan TTL tepat
- Pastikan read API deterministik dan mudah di-cache
- Denormalisasi read model jika perlu
- Baru pertimbangkan search index atau storage khusus
Setiap langkah seharusnya dipicu oleh bukti bottleneck, bukan asumsi.
- Cache + async side effects
- Optimasi query & schema
- Read model terpisah (denormalized)
- Elasticsearch (jika memang dibutuhkan)
Hindari premature complexity.
Checklist Sebelum Masuk Production
Sebelum menerapkan arsitektur read-heavy seperti yang dibahas di artikel ini ke environment production, gunakan checklist berikut untuk memastikan desain yang dibuat benar-benar dibutuhkan dan siap dijalankan.
Checklist Teknis
- Apakah read traffic sudah atau diproyeksikan jauh lebih besar dibanding write?
- Apakah endpoint product page sudah dipastikan bebas side-effect sinkron?
- Apakah setiap domain data memiliki TTL yang jelas dan masuk akal?
- Apakah strategi cache invalidation sudah ditentukan (event-based / TTL)?
- Apakah cache hit ratio dapat dimonitor (metrics & alert)?
- Apakah fallback behavior saat cache miss atau partial failure sudah didefinisikan?
- Apakah BFF mampu melakukan parallel fetch dan timeout isolation?
Checklist Operasional
- Apakah tim siap mengoperasikan Redis / cache layer dengan baik?
- Apakah message broker / queue untuk side-effect async sudah tersedia?
- Apakah observability (log, metrics, tracing) mencakup read path?
- Apakah tim memahami trade-off eventual consistency pada read model?
Jika sebagian besar checklist di atas belum terpenuhi, ada baiknya menunda kompleksitas dan memperbaiki fondasi terlebih dahulu.
Kapan Arsitektur Ini Tidak Perlu (Hindari Over-Engineering)
Tidak semua sistem membutuhkan arsitektur read-heavy yang kompleks. Dalam kondisi tertentu, pendekatan ini justru bisa menjadi beban.
Arsitektur ini belum perlu diterapkan jika:
- Traffic masih rendah dan stabil
- Product page jarang diakses bersamaan
- Data masih sering berubah struktur
- Tim kecil dan fokus pada validasi produk
- Bottleneck belum terbukti berasal dari read load
Pada fase awal, solusi yang sering lebih tepat adalah:
- Satu endpoint sederhana
- Query yang jelas dan terukur
- Index database yang memadai
- Cache minimal atau bahkan tanpa cache
Prinsip pentingnya:
Jangan memecahkan masalah yang belum ada.
Arsitektur yang baik adalah arsitektur yang cukup, bukan yang paling canggih.
Penutup
Arsitektur read-heavy yang baik bukan soal teknologi paling canggih, tapi soal:
- Memahami karakteristik data
- Menghormati jalur read sebagai hot path
- Memisahkan concern dengan jelas
- Mengutamakan cache dan async processing
Pendekatan composable read API + BFF + cache berlapis telah terbukti mampu menangani traffic besar dengan resource database yang terbatas.
Jika product page adalah jantung aplikasi, maka read API adalah nadinya—buatlah ia ringan, cepat, dan tahan tekanan.